

Understanding the Black Box - Part 1
Agents are opaque and we are embedding them into every digital interaction that we have

Since the launch 2022, LLMs built on the transformer architecture such as ChatGPT, Gemini, and Claude have reshaped the world with their ability to produce remarkably human-like text. Today 2025, we are witnessing their rapid adoption into images and videos, through OpenAI’s Sora, Meta’s Vibes, and xAI’s Grok. Yet behind this astonishing capability lies a deep mystery:
we still don’t fully understand how these systems function.
Traditional software is explicitly programmed by humans, written line by line in interpretable code. LLMs, however, are not designed in this way; they are trained. Their behaviour emerges from learning to predict the next word across immense amounts of internet text, producing a dense web of trillions of parameters that somehow encode knowledge, reasoning, and creativity. This process yields extraordinary performance but little transparency. These models are undeniably powerful, yet the mechanisms driving their success remain largely opaque.
As AI adoption accelerates understanding why LLMs say what they say has become paramount. This is where mechanistic interpretability comes in: the field dedicated to uncovering the inner workings of these black boxes and bringing clarity to the most powerful technology of our time.
As an investor in AI, I often find it difficult to distinguish genuine innovation from noise. Every technological wave attracts opportunistic or casual entrepreneurs , and the AI boom is no exception.
With software itself becoming increasingly Agentic, understanding the brain behind these agents has never been more crucial so these series of essays explores the inner mechanics of LLMs: how they learn, represent knowledge, and generate meaning.
My goal is to explores the inner mechanics of LLM, both to deepen my understanding and to help navigate the AI investment landscape with greater insight.
Today the transformer, an ML model architecture introduced in 2017, is the most popular architecture for building LLMs. How a transformer LLM works depends on whether the model is generating text (inference) or learning from training data (training).
LLMs during Training
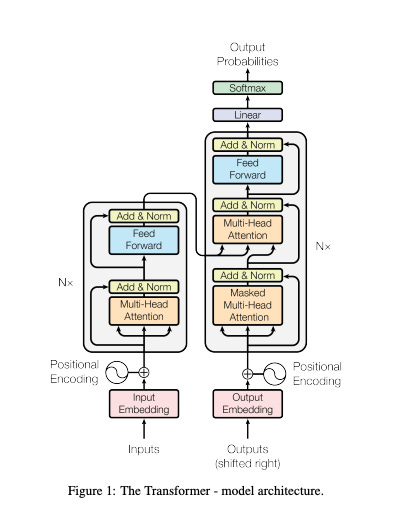
During training, the transformer produces predictions for every token in a sentence. For each input position i, the model predicts the token that follows it, i + 1. Generating multiple predictions simultaneously allows for more efficient training.
These predictions are compared against the actual tokens in the training data, and the resulting errors are used to adjust the model’s parameters to improve its performance.
Step 1 - Tokenization: converting text into tokens
When the model receives a sentence such as “Bright stars shine tonight,” it first splits the text into smaller units called tokens. A token could be a complete word (e.g., “bright”), a segment of a word (e.g., “shine” and “s” from “shines”), or punctuation.
Each token in the model’s vocabulary is then mapped to a unique numeric ID. For example, “Bright stars shine tonight” might be represented as [21, 58, 77, 204]. This numeric sequence is the tokenized version of the text, produced by the tokenizer.
The model then adds positional embeddings to these token vectors to encode the order in which the tokens appear in the sentence..
Step 2 - Embeddings: giving meaning to tokens
After text is broken into tokens, each token is turned into an embedding vector, which is a list of numbers that represents its meaning. By multiplying the list of token IDs by an embedding matrix.
The embedding matrix has a size of[vocabulary size, embedding dimension], meaning:
• Each word in the vocabulary has one row.
• Each row is the embedding vector for that token.
So how do these vectors capture meaning?
During training, the model learns to assign similar vectors to words with similar meanings such as “see,” “look,” and “watch.” In this high-dimensional space, similar words end up pointing in similar directions, so the angle between their vectors is small.
What is an embedding vector?
An embedding vector is a list of numbers that represents each token’s meaning.
Step 3 - The residual stream: How data flows
Inside a transformer, information moves through something called the residual stream. They are a shared workspace where different parts of the model write down and read information. Each transformer layer takes the current information in the stream, updates it, and passes it along.
At the start, the residual stream only contains the individual meaning of each word, without context. As the data flows through the transformer blocks, each layer refines those meanings by taking previous words into account. Over time, the model builds a richer understanding of each token in context.
Residual Stream Technical Architecture:
This stream is simply a list of vectors, one for each token in the input. Its shape is [sequence length, model dimension], which matches the shape of the embedding layer’s output.

Source: Exploring the Residual Stream of Transformers
LLM architecture are an advance deep learning model, my intention is that this does not become overwhelming for readers, I keep dissecting their inner workings in following posts
If you want to dig deeper and check sources:
https://arxiv.org/html/2312.12141v1
https://arbs.io/2024-01-14-demystifying-tokens-and-embeddings-in-llm
https://www.lesswrong.com/posts/XGHf7EY3CK4KorBpw/understanding-llms-insights-from-mechanistic
Excellent analysis, you articulate the black box issue perfectly. Given the 'trillions of parameters' and the rise of 'Agentic' software, how do you see mechanistic interpretability scaling efectively?